为什么需要把图片里的文字抠出来?
日常工作中,我们总会遇到扫描件、截图、海报、PPT照片等场景,文字被锁死在像素里,手动敲一遍既费时又容易出错。把图片文字提取成可编辑文本,能直接解决以下痛点:

(图片来源网络,侵删)
- 效率提升:一篇页数较多的合同,OCR后分钟级完成全文搜索与修改。
- 资料归档:将纸质档案批量电子化,方便后续检索。
- 内容再利用:把网络截图里的金句快速引用到报告或推文。
图片文字提取到底难在哪?
看似简单,实则暗藏三大技术门槛:
- 图像质量:手机抖动、光线阴影、低分辨率都会让字符边缘模糊。
- 版式复杂:表格、双栏、竖排、图文混排,传统OCR容易串行或漏行。
- 语言混合:中英文、数字、特殊符号夹杂,需要多语言模型同时支持。
主流OCR技术路线对比
1. 传统引擎:Tesseract
开源老将,本地部署无网络依赖,适合大批量离线处理。但对中文支持需额外训练字库,复杂版式识别率仅70%左右。
2. 云服务:百度/腾讯/阿里OCR
通过API调用,识别率95%+,支持表格还原、印章检测、手写体。缺点是需要上传图片,涉密文件慎用。
3. 端侧AI:PaddleOCR、RapidOCR
兼顾隐私与精度,可在无网环境运行,手机端也能实时识别。模型体积约20MB,适合App集成。
如何自己手动提取?零门槛三步法
不想装软件?微信就能搞定:

(图片来源网络,侵删)
- 把图片发到“文件传输助手”,长按图片选择“提取文字”。
- 框选需要段落,一键复制到剪贴板。
- 粘贴到Word或备忘录,自动保留换行。
实测对印刷体准确率90%,手写体稍弱。
专业级批量提取方案
如果需要一次性处理上千张扫描件,推荐以下组合:
- 硬件:馈纸式扫描仪(支持双面自动进纸)。
- 软件:ABBYY FineReader 或 天若OCR(开源+插件)。
- 流程:扫描→批量OCR→按文件名自动保存为双层PDF。
ABBYY的版面分析功能可还原原文档的表格、标题层级,后期几乎不用再排版。
图片文字识别软件哪个好用?横向评测
| 名称 | 准确率 | 是否免费 | 特色功能 |
|---|---|---|---|
| 微信提取文字 | 90% | 完全免费 | 无需安装,即用即走 |
| 天若OCR | 93% | 开源免费 | 支持截图识别+翻译 |
| PandaOCR | 95% | 个人免费 | 内置12种云接口可切换 |
| ABBYY FineReader | 98% | 付费 | 保留排版,支持PDF对比 |
结论:日常轻量需求选微信或天若,专业出版级选ABBYY。
常见疑问快问快答
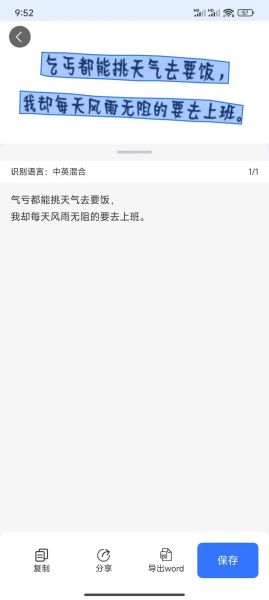
Q:截图模糊还能识别吗?
A:先用waifu2x或Photoshop「智能锐化」提升分辨率,再导入OCR,准确率可提升20%。
(图片来源网络,侵删)
Q:PDF是扫描版,怎么转Word?
A:用Adobe Acrobat的「增强扫描」功能先纠偏,再导出为可编辑Word,表格会保留边框。
Q:手机端离线识别如何部署?
A:下载PaddleOCR安卓Demo,把轻量模型(ch_ppocr_mobile)放到assets目录,即可在无网环境运行。
避坑指南:提高识别率的五个细节
- 拍摄角度:保持镜头与纸面垂直,避免梯形畸变。
- 光线均匀:使用台灯补光,减少手指阴影。
- 分辨率:至少300dpi,手机拍照请开启高像素模式。
- 背景干净:纯色桌面比花纹桌布干扰更少。
- 语言设置:提前在OCR软件里勾选“中英文+数字”,避免系统误判为日文。
进阶玩法:把OCR接入自动化工作流
利用Python+阿里云OCR API,可实现以下场景:
import requests, base64, json
with open('invoice.jpg','rb') as f:
img = base64.b64encode(f.read()).decode()
data = {'image': img}
resp = requests.post('https://ocr.aliyun.com/invoice', json=data)
print(json.loads(resp.text)['amount'])
每天定时扫描邮箱附件,自动提取发票金额并填入Excel,全程零人工。
评论列表